The following piece was first published on the Data Empowerment blog and was originally published on November 1, 2020.
So far we’ve looked at how access to data can empower people and argued that ensuring people have actionable data is even more critical in the ‘trying times’ we find ourselves in.
In this post, we’re diving deeper into the question of how to exercise control over one’s data, which, as you might recall, we view as the second key element of the data empowerment concept: “the process where people, on their own or with the help of intermediaries, take control — or gain the power to take control — of their data to promote their and their society’s wellbeing.”
But how would such ‘control-taking’ work in practice? Who should be at the center of the process? And can third parties play an active role in helping people take control of ‘their’ data?
Losing control
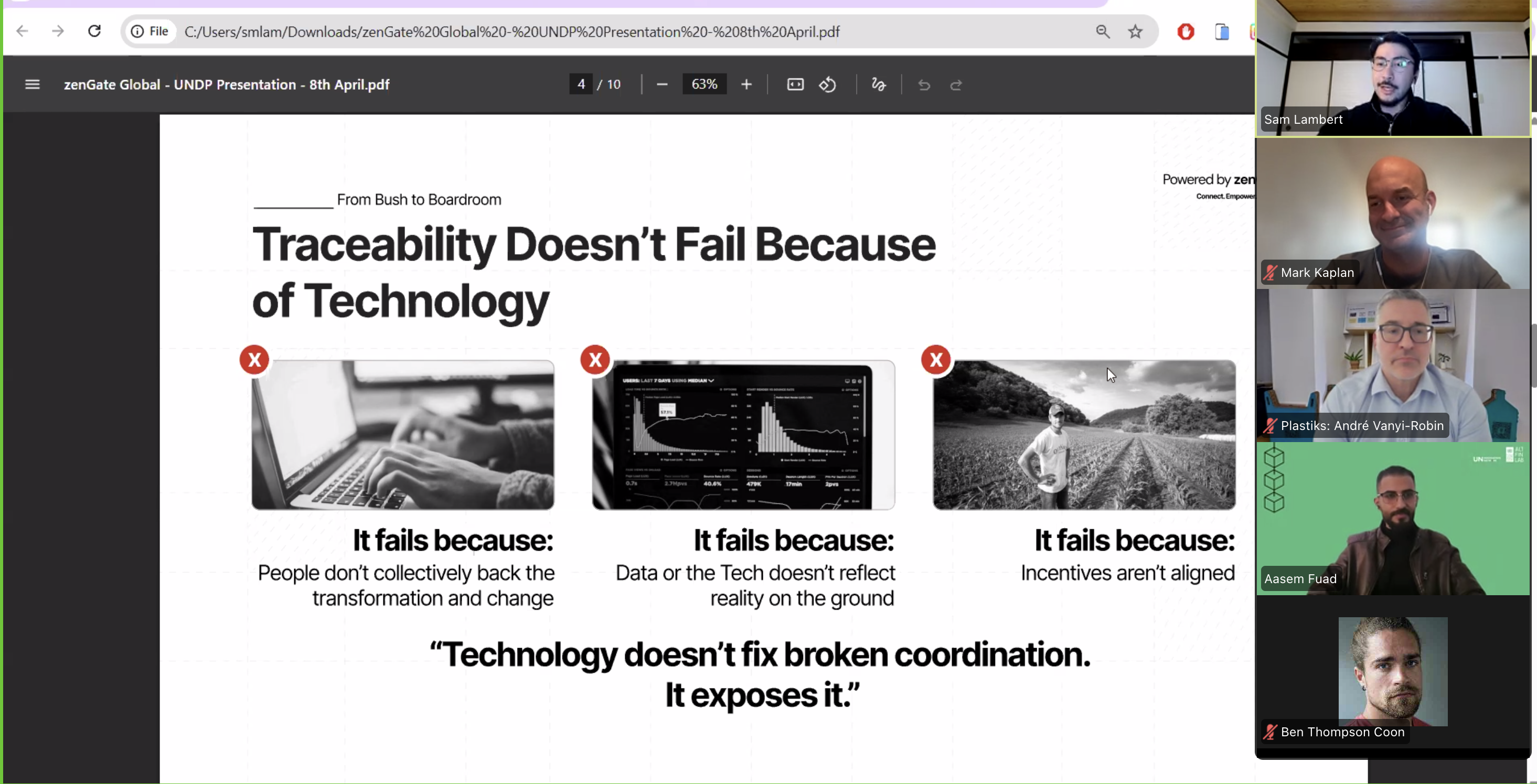
If there is one thing data governance experts agree on, it’s this: we have lost control of the data being collected, used and shared about us. The data we generate when searching online, posting a photo or sending a message is stored, analyzed and sold “in ways that we can neither see nor imagine”. Where they disagree is what we should do about it.
Let’s start by looking at some of the existing perspectives to see which, if any, is suited to inform and shape the data empowerment concept.
The individual perspective
For proponents of the individual-focused data governance approach, also referred to as the “individual control group”, the solution is straightforward: all we need to do is give people more (individual) control over their data. Bound only by legal constraints, it’s every individual’s responsibility to decide how ‘their’ data is used. They would do this through, for example, strengthened informed consent mechanisms that give people more control over data flows, Personal Management Information Systems like Digi.me to automate consent for different types of data, and personal data trading platforms like UBDI that allow people to get a monetary share of the value created by data markets.
The collective perspective
Others argue that such individualistic, or even hyper-individualistic, approaches to data governance just won’t work in a world where so much data surrounds us, as it would require a near-impossible number of decisions every day:
“Just as it would be ludicrous to expect any one person to individually evaluate whether the air they breathe is toxic every time they inhale, we cannot expect people to make a million tiny decisions about their data on a daily basis.” — Anouk Ruhaak
What’s more, even if we were able to read through the privacy policies for each service we use, which according to one study would take an individual 30 workdays per year, the collective impact of our data use calls for collective approaches to govern data. For example, as increasingly powerful machine learning technologies infer characteristics about us based on data about people like us, other people’s data can impact us as much as the data we generate ourselves. This means that giving individuals more control over ‘their’ data would not allow them full control over how data about them is used.
Instead of putting the individual at the center, collective data governance models, including certain types of data cooperatives, focus on the collaborative pooling of data by individuals and collective control to address the limitations that come with the individual-focused approach.
The intermediated perspective
Proponents of intermediated models agree with collectivists that the individual is not (always) the most appropriate level of decision-making and control when it comes to data. However, they also question the ability of groups to make choices that are in the interest of every member. In intermediated data governance models, certain rights are transferred to trusted and independent third parties. As the most prominent practical example of an intermediated, or more accurately, fiduciary model, data trusts are increasingly being viewed as a powerful mechanism for a fair, just and participatory form of data governance. There are different understandings of what data trusts are and how they work, but the general idea is to place control over someone’s data with trustees who have a fiduciary responsibility to look after the interests of the data subjects. Data trusts require complicated legal and technical arrangements which is one of the reasons that practical experiences remain limited.
Which of these three approaches can enable data empowerment?
We don’t yet have a definite answer on how to handle and govern ‘our’ data and what perspective is best suited to shape the data empowerment concept. However, we do recognize the limitations of the approaches and models that put the individual at the centre. Having more of a say in how one’s data is used, does not automatically result in greater control, actual decision-making power or agency. And so we see value in exploring in more depth the practical use of collective and fiduciary approaches, including data trusts, data cooperatives and certain forms of data commons models that could facilitate more inclusive and fair data governance and data sharing. We might also try to learn from community consent mechanisms and group privacy approaches that look beyond those whose data is collected but consider everyone in a group who will be affected, to see if they can address some of the shortcomings of informed consent.
We will be writing in more depth about how data, and therefore power, can be governed to help you make sense of the many concepts, and their variations, out there. Do get in touch if you want to connect with us.
Illustrations: Vincent Beck